Contextual Imagined Goals for
Self-Supervised Robotic Learning
Ashvin Nair*, Shikhar Bahl*, Alexander Khazatsky*, Vitchyr Pong, Glen Berseth, Sergey Levine
- University of California, Berkeley
- *Equal Contribution
- paper / code / envs / data
Abstract
While reinforcement learning provides an appealing formalism for learning individual skills, a general-purpose robotic system must be able to master an extensive repertoire of behaviors. Instead of learning a large collection of skills individually, can we instead enable a robot to propose and practice its own behaviors automatically, learning about the affordances and behaviors that it can perform in its environment, such that it can then repurpose this knowledge once a new task is commanded by the user? In this paper, we study this question in the context of self-supervised goal-conditioned reinforcement learning. A central challenge in this learning regime is the problem of goal setting: in order to practice useful skills, the robot must be able to autonomously set goals that are feasible but diverse. When the robot's environment and available objects vary, as they do in most open-world settings, the robot must propose to itself only those goals that it can accomplish in its present setting with the objects that are at hand. Previous work only studies self-supervised goal-conditioned RL in a single-environment setting, where goal proposals come from the robot's past experience or a generative model are sufficient. In more diverse settings, this frequently leads to impossible goals and, as we show experimentally, prevents effective learning. We propose a conditional goal-setting model that aims to propose goals that are feasible from the robot's current state. We demonstrate that this enables self-supervised goal-conditioned off-policy learning with raw image observations in the real world, enabling a robot to manipulate a variety of objects and generalize to new objects that were not seen during training.
Method
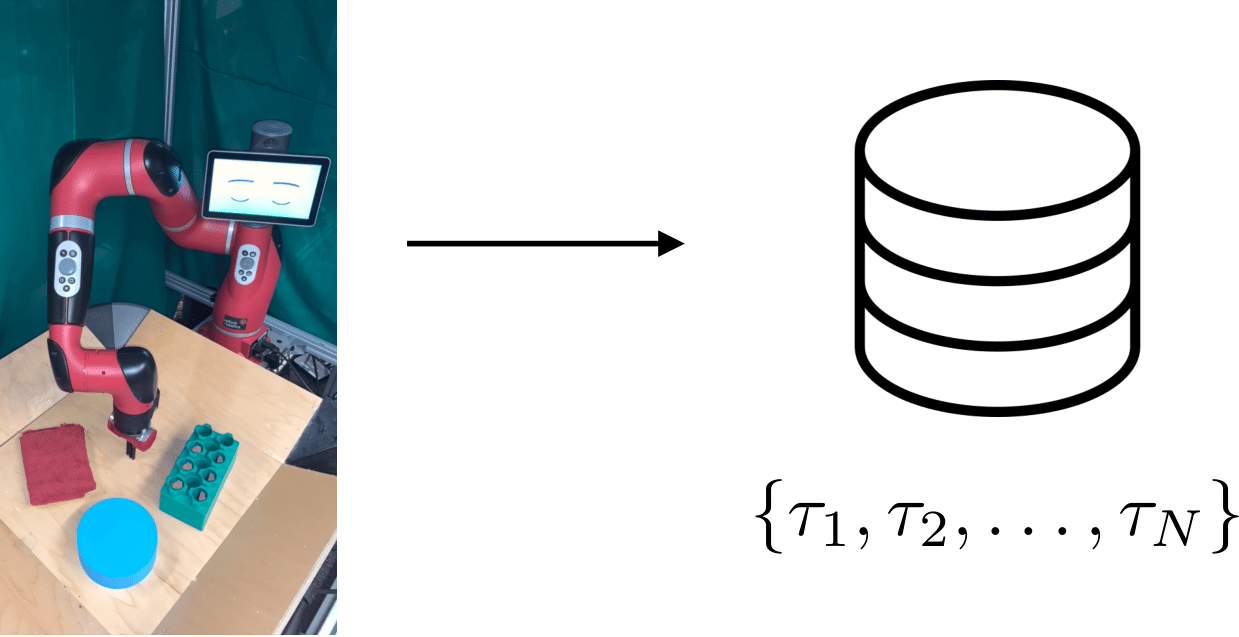
1. The robot collects random interaction data, to be used for training a representation and as off-policy data for RL.
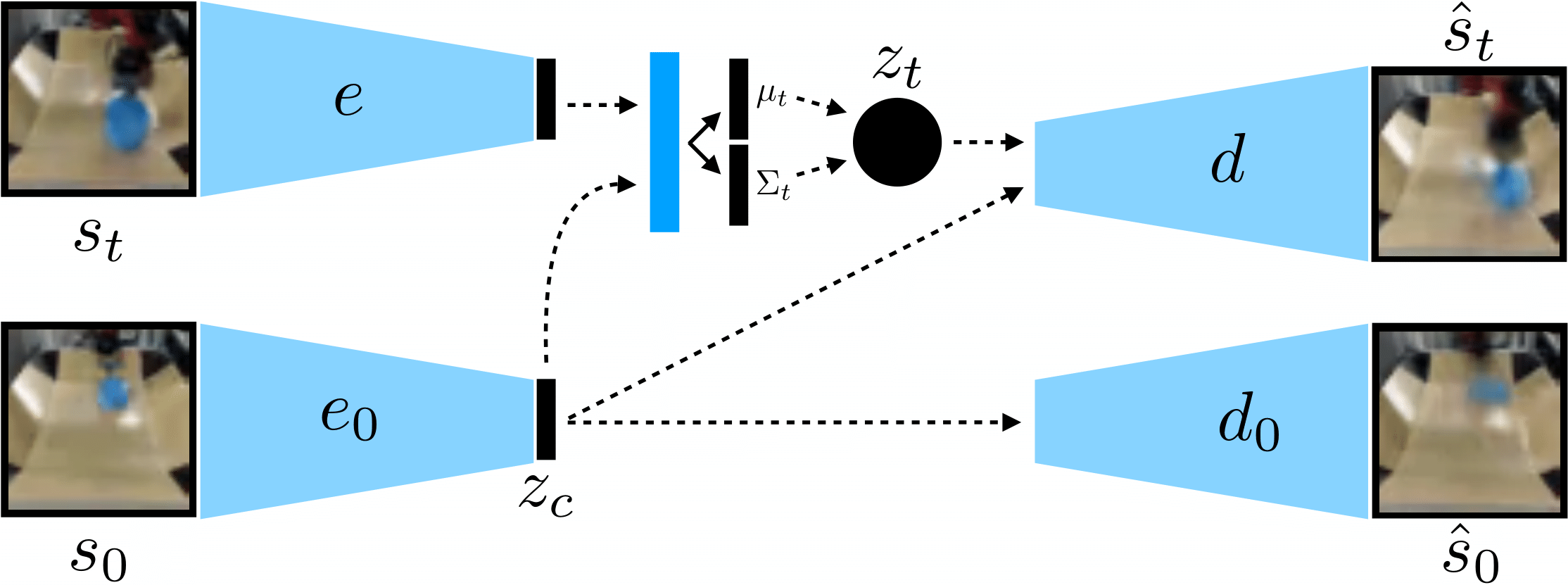
2. We train a context-conditioned VAE on the data, which disentangles context that stays constant during a rollout.
3. At training time, the robot learns a policy with RL to minimize the latent distance to a generated goal.
4. At test time, the robot is provided a goal image and executes the policy to reach the goal image.
Video
Simulation Environments
Multi-Color Pusher: the agent is tasked with pushing a puck to a goal location indicated by a goal image. The color of the puck changes to a random RGB value at the start of every rollout.
Multi-Color 2D Navigation: the agent controls a pointmass and must reach a target position indicated by a goal image, while navigating around the walls. The color of the pointmass changes to a random RGB value and the walls change to one of 15 orientations at the start of every rollout.
Paper
Preprint can be accessed on arXiv.
Code
The visually diverse environments are available at github.com/vitchyr/multiworld. Algorithm code is available at github.com/anair13/rlkit/tree/ccrig/examples/ccrig.
Data
Our real-world pushing data is available at this link. There is a notebook inside with example loading code. It contains 20 objects - 88,000 transitions (about 5 hours) of data.
Citation
@inproceedings{nair19ccrig,
author = {A. Nair and S. Bahl and A. Khazatsky and V. Pong and G. Berseth and S. Levine},
title = {Contextual Imagined Goals for Self-Supervised Robotic Learning},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2019}
}